A new Block on the Desk: Extract Entities
Posted on 30/06/2021 by Hendrik Werner

At Spinque, we have recently launched a pilot project to integrate Artificial Intelligence (AI) into the strategy builder. Specifically, we have built BERT into Spinque Desk as a building block, such that it can be used as part of a search strategy. This work was done during the course of the research internship for my Data Science master's degree.
BERT is a model architecture which can perform many Natural Language Processing (NLP) tasks with state-of-the-art performance. NLP lies at the intersection of linguistics, computer science, and AI, and deals with automating the processing and analysis of natural language data. Currently, we solely provide models for Named Entity Recognition (NER), but this can easily be extended to other tasks, should there be demand. NER is a subtask of NLP concerned with recognizing named entities (persons, organizations, locations, etc.) in unstructured data. For an example, refer to the header image, in which several types of named entities have been tagged.
This blog post covers Machine Learning in general, the accessibility problems it usually comes with, as well as the solution we came up with. A complete step by step example is given for how to use BERT as part of a search strategy, and finally future directions are discussed.
Machine Learning
Over the last few decades, the field of Machine Learning (ML) and Artificial Intelligence has seen significant advances across a multitude of diverse domains. ML-driven systems represent the state-of-the-art in countless fields such as image and speech recognition and generation, Natural Language Processing, materials science, and many more. These systems, whose scope and performance are improving rapidly, have long been shown to outperform traditional approaches relying on inference rules carefully and labor-intensively hand-crafted by domain experts. It is hard to find an industry that has not been impacted by the use of ML.
Moreover, these systems can be trained automatically by computers (hence the name "Machine Learning"), thus representing a new era of AI, in which models can relatively quickly and easily be adapted to new datasets. Additionally, advances in ML techniques can quickly permeate through the entire ecosystem. This reduces the need for domain experts and speeds up turnaround times. Given a dataset, a suitable model architecture, and some computing time, a non-domain-expert is able to train AI models that perform exceptionally well.
At this point, it should be mentioned that ML-driven AI models are no panacea, and they come with distinct disadvantages. AI models trained through ML are often black box systems with unexpected and often counter-intuitive failure-modes and hidden biases. The majority of models are trained though mathematical optimization techniques refining millions, or even billions of parameters, representing exceedingly complicated high-dimensional functions. Thus, their inferences are mostly uninterpretable for humans. This means that it is often unclear how AI models achieve their impressive performance, and the domain knowledge they extracted from the data to reach it is inaccessible. It is also nearly impossible to predict when and how these systems will fail.

In computing, there is also the old adage "garbage in, garbage out", which refers to the fact that the output of any system can only be as accurate as the input it receives. ML systems learn from the data that is provided to them, so the quality of the dataset is of utmost importance. Biases and mislabeled instances will be picked up and incorporated by the models trained on this data. Contemporary ML approaches typically require large datasets to perform well, which stand in the way of ensuring their quality.
With that said, if one wants best-in-class performance in a large number of areas, training Artificial Intelligence models through Machine Learning is the way to go.
Accessibility
Contemporary ML systems remain largely inaccessible to non-technical users, requiring Data Science expertise which is not widely available outside of the field. Most of them are neither intuitive nor easy to use. They do not require domain experts, but still have to be operated by ML specialists.
At Spinque, we have some experience with taking very useful and widely applicable yet unergonomic technology and making it accessible to a general audience. With the BERT pilot project, we are taking the next step, by making a state-of-the-art NLP model available as a nicely-integrated part of our SaaS platform. Trained models are exposed as blocks in the Strategy Builder, where they can be used to perform tasks such as Named Entity Recognition.
BERT is a recent general-purpose NLP model, which can be adapted to a large variety of tasks, achieving state-of-the-art performance in many of them. It is trained in two steps:
- pre-training, during which the model learns context-sensitive embeddings on a very large dataset
- fine-tuning, which adapts the model for some specific task.
During pre-training, the model is trained on a very large dataset, using unsupervised tasks. This allows it to extract robust and generic context-sensitive word embeddings, which are useful across a wide range of tasks. Due to the size of the datasets involved, this training step is pretty resource- and time-intensive. However, it only needs to be performed once, and the resulting model can be cheaply adapted to the downstream task at hand during the fine-tuning step. Pre-trained models are available online.
Natural Language Processing at Spinque
Currently, we offer an ensemble of pre-trained and fine-tuned BERT models ready for inference. They have been generated by taking a pre-trained BERT model and fine-tuning it on a dataset matching the downstream NLP task to be performed, for example Named Entity Recognition (NER). Simply select a model matching the task you want to perform, then connect it to other blocks to integrate it into your search strategy.
Most BERT models are language-specific, as pre-training and fine-tuning are performed on a dataset in a single language. They may of may not work when given input in a different language. There have been attempts at multilingual BERT models, but they generally perform worse compared to their monoglot counterparts. At the time of writing, we provide English and Dutch models. Make sure to select a model matching the language of your data.
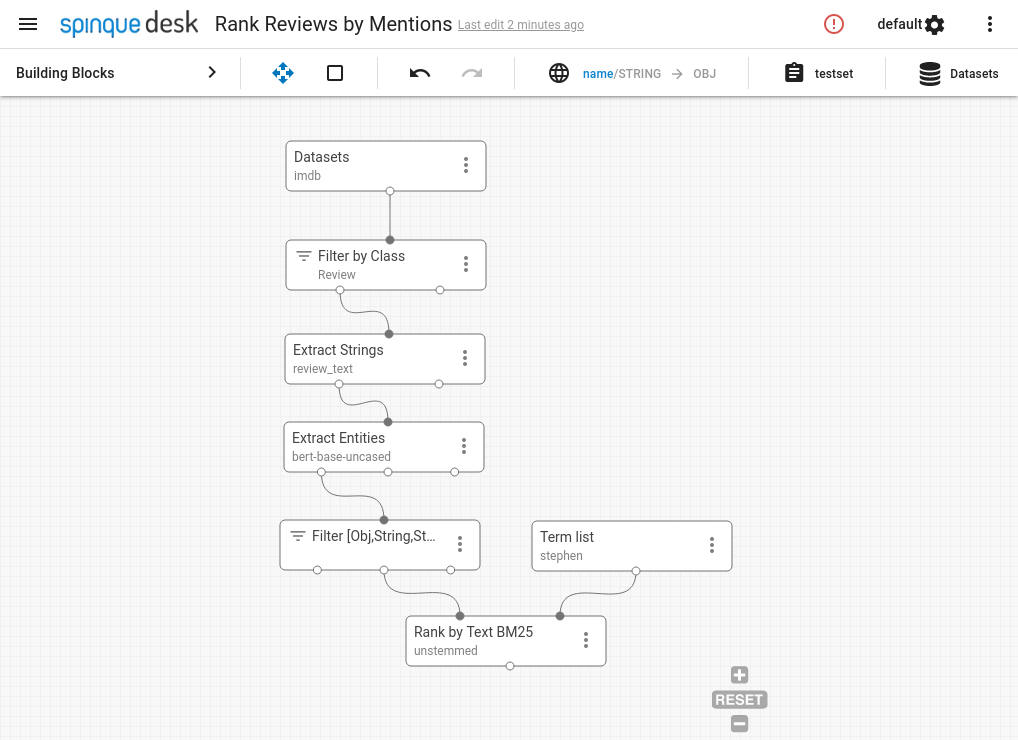
Now, we will walk step by step through the creation of a search strategy employing BERT to perform NER on an English dataset.
- Navigate to Spinque Desk:
- Select the "Strategies" tab:
- Create a new strategy, by clicking the "+" in the lower right corner.
- Import a dataset. For this example, we will use the IMDB sample dataset, which consists of English movie reviews.
- Filter for the class we are interested in, namely reviews.
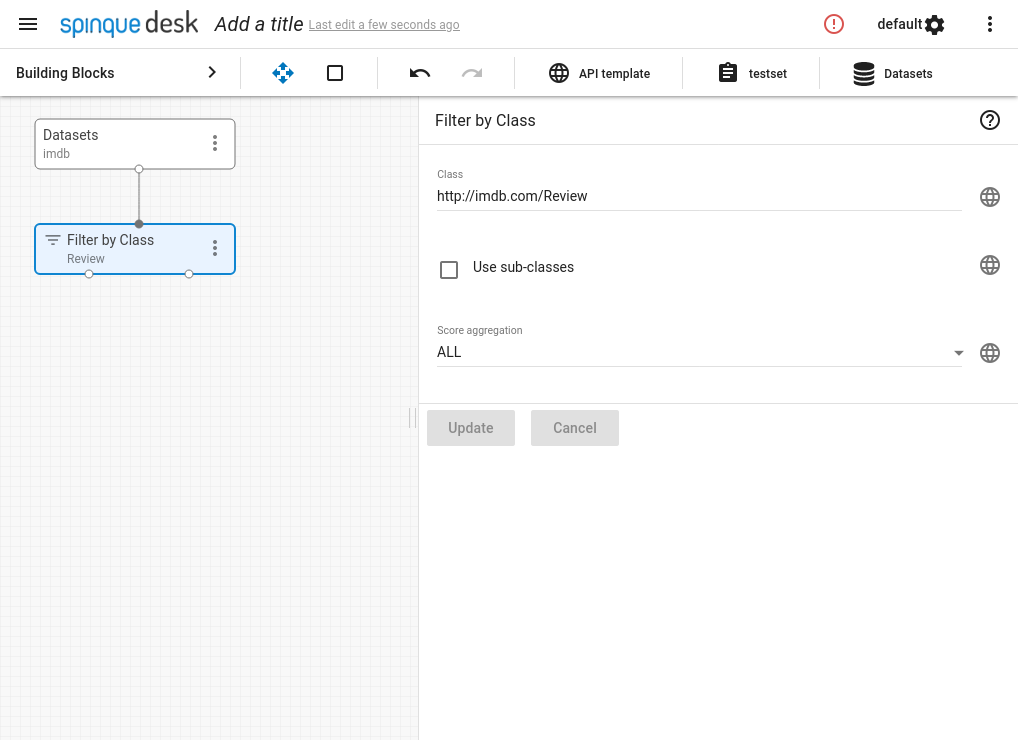
- Extract the review text. BERT takes text inputs, and the review text is what it will actually operate on.
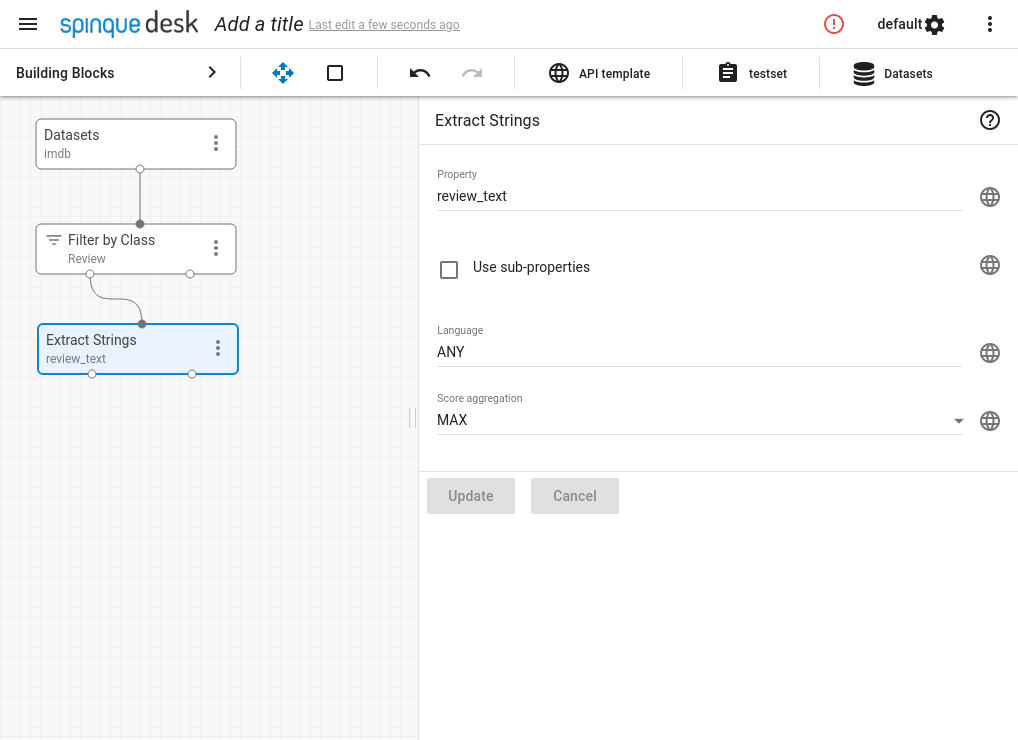
- Now that we have the prerequisites in place, we can use the Extract Entities block, which employs BERT internally. Since our data is in English, we use the English "bert-base-uncased" model, fine-tuned on the English "Kaggle" NER dataset.
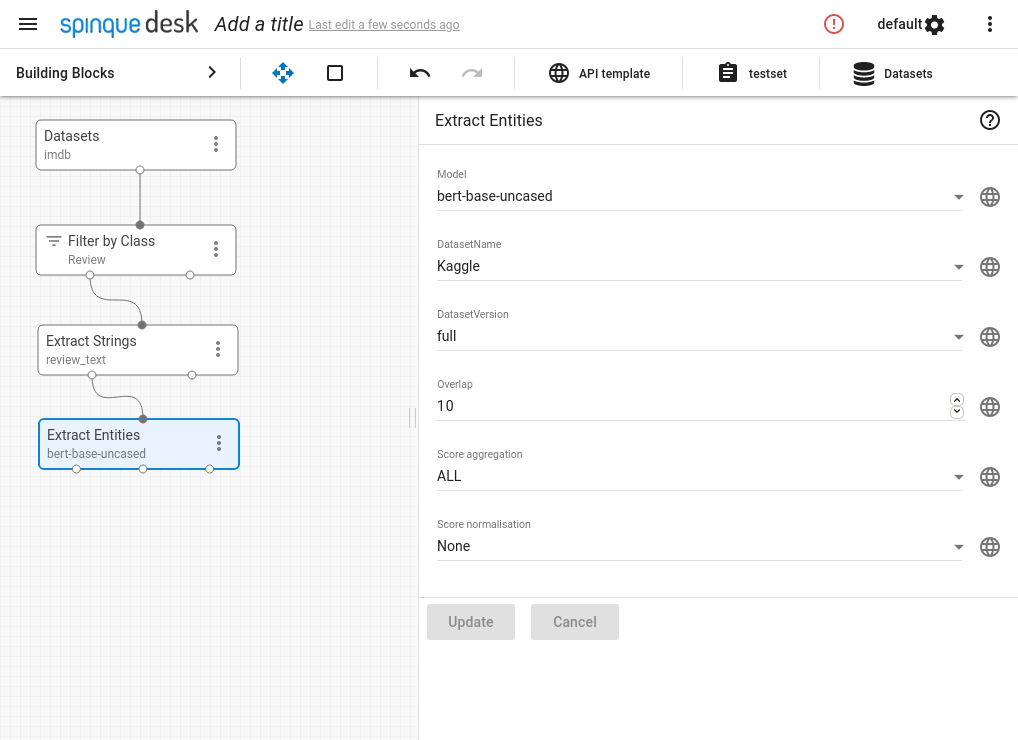
- Connect output to some block. The Extract Entities block has three outputs: (document, entity) and (document, entity type) pairs, as well as (document, entity, entity type) triples. The pairs can easily be connected to a lot of blocks, while the full triple necessitates some special handling. This is because few blocks can accept triples as inputs.
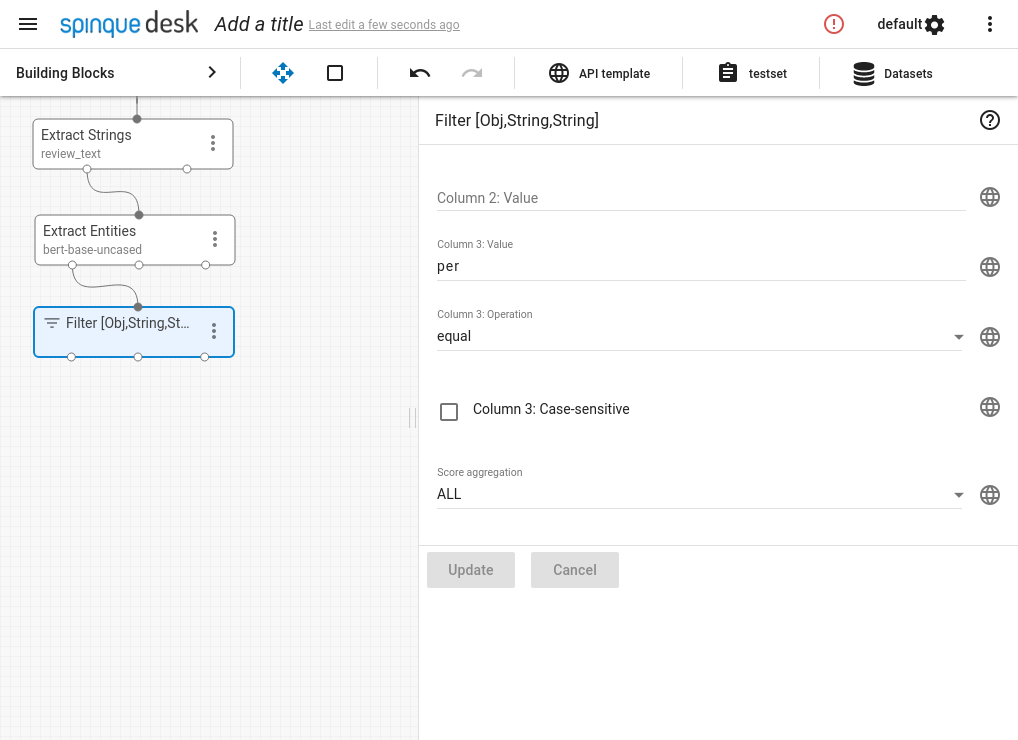
- That's it! Now we have an output which contains (document, person name) pairs. It can be connected to other blocks and used as part of a larger strategy.

Future Directions
Currently, we only offer Named Entity Recognition models for English and Dutch. In the future, we plan on adding more datasets, including different languages. We also intend to support additional NLP tasks using BERT, or even expand into other ML models. BERT's genericity affords us a lot of flexibility, in that we only need a suitable dataset to fine-tune models for new tasks.
Research is being conducted into training personalized models on-demand, such that you would no longer have to choose between ready-made generic models. Instead, one could fine-tune a personalized model for each specific task. The main road block holding this idea back is the requirement for labeled data during the fine-tuning step. We are exploring Active Learning approaches, as well as automatic dataset extraction from knowledge graphs.
Personalized models would not even be limited to specific predefined NLP tasks such as NER, but could instead be trained on whatever task is required for the search strategy at hand. BERT itself is very general, and can theoretically perform any type of sentence/word prediction, sequence/token classification, question answering, multiple-choice selection, and probably more. If you provide a suitable dataset, BERT can learn the task.